





引言:GPT的错误挑战
随着人工智能技术的飞速发展,自然语言处理(NLP)领域取得了显著的进步。GPT(Generative Pre-trained Transformer)作为一种先进的NLP模型,在文本生成、机器翻译、问答系统等方面展现出强大的能力。然而,尽管GPT在许多任务上表现出色,但其错误不断的问题也引起了广泛关注。
模型复杂性带来的挑战
GPT模型的复杂性是其强大功能的基础,但同时也带来了错误的风险。首先,GPT模型通常需要大量的数据进行训练,这可能导致模型在处理未知或罕见数据时出现错误。其次,GPT模型的结构复杂,参数众多,这使得模型在优化过程中容易出现局部最优解,从而导致错误。
数据偏差与错误
在GPT的训练过程中,数据的质量和多样性对模型的性能至关重要。然而,由于数据集可能存在偏差,GPT在处理某些特定问题时可能会产生错误。例如,如果训练数据中包含性别歧视或种族歧视的表述,GPT在生成相关文本时可能会无意中传播这些偏见。这种数据偏差导致的错误是GPT面临的一大挑战。
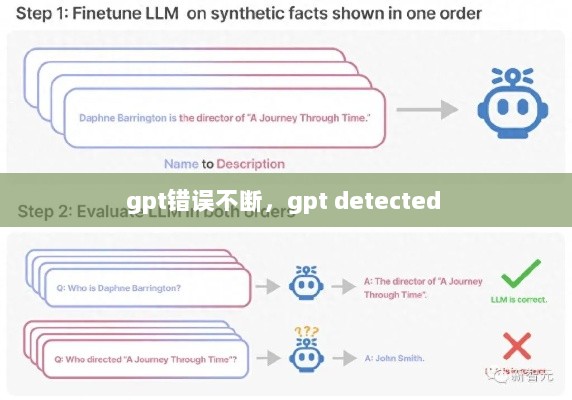
模型泛化能力不足
尽管GPT在特定任务上表现出色,但其泛化能力仍然有限。这意味着GPT在处理与训练数据相似但略有不同的问题时,可能会出现错误。例如,GPT在生成新闻报道时可能会错误地引用不存在的新闻事件,或者在回答问题时提供不准确的信息。这种泛化能力不足的问题在GPT的实际应用中尤为突出。
错误检测与纠正
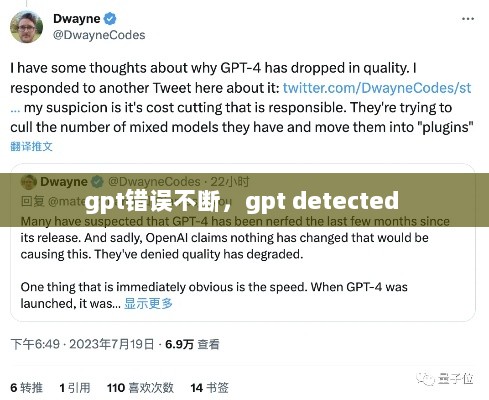
为了解决GPT的错误问题,研究人员和开发者正在努力提高错误检测与纠正的能力。一方面,通过改进训练算法和优化模型结构,可以降低GPT在处理未知数据时的错误率。另一方面,开发新的错误检测工具和算法,可以帮助识别和纠正GPT生成的错误文本。例如,一些研究提出了基于对抗样本的方法来检测GPT的错误。

伦理与责任
随着GPT在各个领域的应用越来越广泛,其错误问题也引发了伦理和责任方面的讨论。一方面,GPT的错误可能会对用户造成误导或伤害,尤其是在医疗、法律等敏感领域。另一方面,如何确保GPT的错误不会加剧社会不平等和歧视现象,也是一个需要认真考虑的问题。因此,开发者和用户都需要对GPT的错误问题负责。
未来展望
尽管GPT的错误问题给其应用带来了挑战,但这也为未来的研究提供了方向。以下是一些可能的未来研究方向:
- 开发更加鲁棒的GPT模型,提高其在处理未知数据时的准确性。
- 研究如何减少数据偏差,提高GPT的公平性和公正性。
- 开发高效的错误检测和纠正工具,帮助用户识别和修正GPT生成的错误。
- 探索GPT在各个领域的应用,并制定相应的伦理规范和责任制度。
总之,GPT的错误问题是一个复杂且多方面的挑战。通过不断的研究和改进,我们有理由相信,GPT的错误问题将得到有效解决,从而为人工智能技术的发展和人类社会的进步做出更大的贡献。







 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...